Abstract
Improving data efficiency and generalization in robotic manipulation remains a core challenge. We propose a novel framework that leverages a pre-trained multimodal image-generation model as a world model to guide policy learning. Exploiting its rich visual-semantic representations and strong generalization across diverse scenes, the model generates open-ended future state predictions that inform downstream manipulation. Coupled with zero-shot low-level control modules, our approach enables general-purpose robotic manipulation without task-specific training. Experiments in both simulation and real-world environments demonstrate that our method achieves effective performance across a wide range of manipulation tasks with no additional data collection or fine-tuning.
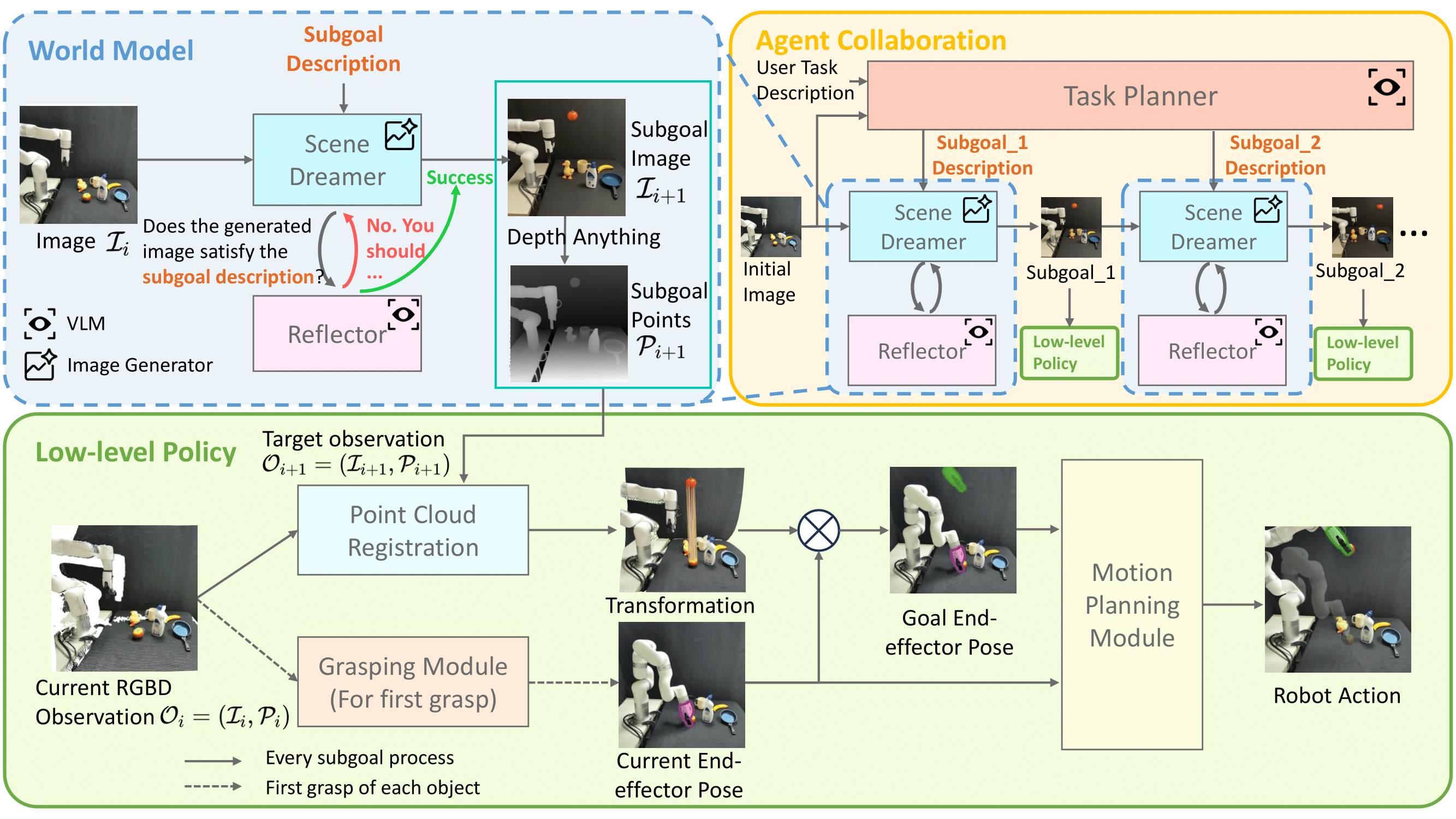
Framework Overview